Sql запити count. Агрегатні функції SQL – SUM, MIN, MAX, AVG, COUNT. Параметри чи аргументи
Щоб визначити кількість записів у таблиці MySQL, необхідно скористатися спеціальною функцією COUNT().
Функція COUNT() повертає кількість записів у таблиці, які відповідають заданому критерію.
Функція COUNT(expr) завжди вважає ті рядки, у яких результатом виразу expr є NOT NULL .
Винятком із цього правила є використання функції COUNT() із зірочкою як аргумент - COUNT(*) . У цьому випадку вважаються всі рядки, незалежно від того, NULL вони або NOT NULL .
Наприклад, функція COUNT(*) повертає загальну кількість записів у таблиці:
SELECT COUNT(*) FROM table_name
Як порахувати кількість записів та вивести на екран
Приклад PHP+MySQL-коду для підрахунку та виведення загальної кількості рядків:
$res = mysql_query("SELECT COUNT(*) FROM table_name") $row = mysql_fetch_row($res); $ total = $ row; // всього записів echo $ total; ?>
Цей приклад ілюструє найпростіший варіант використання функції COUNT(). Але за допомогою цієї функції можна виконувати й інші завдання.
Вказавши певний стовпець таблиці як параметр, функція COUNT(column_name) повертає кількість записів цього стовпця, які містять значення NULL . Записи із значеннями NULL ігноруються.
SELECT COUNT(column_name) FROM table_name
Використовувати функцію mysql_num_rows() не можна, тому що для того, щоб дізнатися загальну кількість записів, потрібно виконати запит SELECT * FROM db, тобто отримати всі записи, а це небажано, тому краще використовувати функцію count.
$result = mysql_query("SELECT COUNT(*) як rec FROM db");
Використання функції COUNT() на прикладі
Ось ще один приклад використання функції COUNT(). Допустимо, є таблиця ice_cream з каталогом морозива, в якій знаходяться ідентифікатори категорій та назви морозива.
SQL - Урок 8. Угруповання записів та функція COUNT()
Згадаймо, які повідомлення і в яких темах у нас є. Для цього можна скористатися звичним запитом:
А якщо нам треба лише дізнатися скільки повідомлень на форумі є. Для цього можна скористатися вбудованою функцією COUNT(). Ця функція підраховує кількість рядків. Причому, якщо як аргумент цієї функції виступає *, то підраховуються всі рядки таблиці. А якщо в якості аргументу вказується ім'я стовпця, то підраховуються ті рядки, які мають значення у зазначеному стовпці.
У прикладі обидва аргументи дадуть однаковий результат, т.к. Усі стовпці таблиці мають тип NOT NULL. Давайте напишемо запит, використовуючи як аргумент стовпець id_topic:
SELECT COUNT(id_topic) FROM posts;

Отже, у наших темах є 4 повідомлення. Але якщо ми хочемо дізнатися скільки повідомлень є в кожній темі. Для цього нам знадобиться згрупувати наші повідомлення за темами та обчислити для кожної групи кількість повідомлень. Для угруповання в SQL використовується оператор GROUP BY. Наш запит тепер виглядатиме так:
SELECT id_topic, COUNT(id_topic) FROM posts GROUP BY id_topic;
Оператор GROUP BYвказує СУБД згрупувати дані по стовпцю id_topic (тобто кожна тема - окрема група) і кожної групи підрахувати кількість рядків:

Ну ось, у темі з id=1 у нас 3 повідомлення, а з id=4 – одне. До речі, якби в полі id_topic були можливі відсутності значень, такі рядки були б об'єднані в окрему групу зі значенням NULL.
Припустимо, що нас цікавлять лише ті групи, які мають більше двох повідомлень. У звичайному запиті ми вказали б умову за допомогою оператора WHERE, але цей оператор вміє працювати тільки з рядками, а для груп ті ж функції виконує оператор HAVING:
SELECT id_topic, COUNT(id_topic) FROM posts GROUP BY id_topic HAVING COUNT(id_topic) > 2;
В результаті маємо:
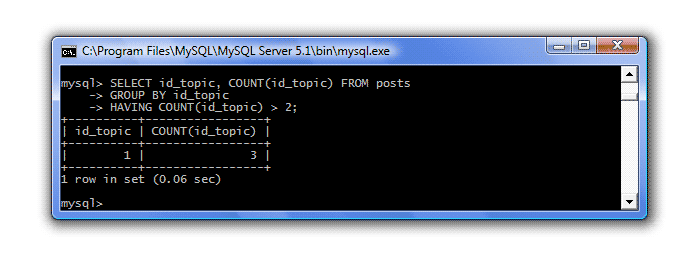
В уроці 4 ми розглядали, які умови можна задавати оператором WHERE, ті самі умови можна задавати і оператором HAVING, тільки треба запам'ятати, що WHEREфільтрує рядки, а HAVING- Групи.
Отже, сьогодні ми дізналися, як створювати групи та як підрахувати кількість рядків у таблиці та групах. Взагалі разом із оператором GROUP BYможна використовувати інші вбудовані функції, але їх ми вивчатимемо пізніше.
є запит виду:
SELECT i.*, COUNT(*) AS Currence, SUM(ig.quantity) AS total, SUM(g.price *ig.quantity) AS price, c.briefly AS cname FROM invoice AS i, invoice_goods AS ig, good g LEFT JOIN currency c ON (c.id = g.currency) WHERE ig.invoice_id = i.id AND g.id = ig.good_id GROUP BY g.currency ORDER BY i.date DESC;
тобто. вибирається список замовлень, в якому вважаються сумарні вартості товарів у різних валютах (валюта встановлена у товару, стовпець cname в результаті - назва валюти)
потрібно в стовпці результату currencies отримувати кількість записів з однаковим i.id , однак експерименти з параметрами COUNT() ні до чого не привели - завжди повертає 1
Питання: чи можливо отримати справжнє значення у стовпці коррень? Тобто. якщо замовлені товари з цінами в 3х різних валютах, currencies = 3?
Занадто великі вільності допускає MySQL по відношенню до SQL, однак. Що, наприклад, означає i.* у контексті цього селекту? Всі колонки таблиці invoice? Так як до них не застосовується жодна групова функція, то непогано було б, щоб вони були перераховані в GROUP BY, інакше не зовсім зрозумілий принцип угруповання рядків. Якщо необхідно отримати всі товари по всіх замовленнях у розрізі валют, це одне, якщо необхідно отримати всі товари згруповані за валютами у розрізі кожного замовлення, це зовсім інше.
Виходячи з вашого селекту, можна припустити наступну структуру даних:
Таблиця invoice:
Таблиця invoice_goods:
Таблиця goods:
Таблиця currency:
Що поверне ваш поточний селект? За ідеєю він поверне для кожного замовлення N-рядок по кожній валюті, в якій у цьому замовленні є товари. Але через те, що в group by не вказано нічого крім g.currency, це не очевидно:), більше того, колонка c.briefly теж робить свій внесок у неявну освіту груп. Що ж ми маємо в результаті, для кожної унікальної комбінації i.*, g.currency і c.briefly буде сформована група до рядків якої будуть застосовані функції SUM та COUNT. Те, що в результаті гри з параметром COUNT у вас виходила завжди 1 означає, що в результуючій групі був тільки один запис (тобто групи формуються не так як вам, можливо, потрібно, можете описати вимоги докладніше?). З вашого питання не ясно, що ви хотіли б дізнатися - скільки різних валют брало участь у замовленні або скільки замовлень було в цій валюті? У першому випадку можливі кілька варіантів залежить від можливостей mySQL, у другому треба по-іншому написати селект вираз.
Занадто великі вільності допускає MySQL по відношенню до SQL, однак. Що, наприклад, означає i.* у контексті цього селекту? Всі колонки таблиці invoice?
Так саме. Але великої ролі не грає, т.к. корисних у разі серед них (колонок) немає. Нехай i.* буде i.id. Для визначеності.
Що поверне ваш поточний селект? За ідеєю він поверне для кожного замовлення N-рядок по кожній валюті, в якій у цьому замовленні є товари. Але через те, що в group by не вказано нічого крім g.currency, це не очевидно:),
Саме так.
Поверне він наступне (у цьому прикладі з я вибираю тільки id, а не всі стовпці):
| id | currencies | total | price | cname |
|---|---|---|---|---|
| 33 | 1 | 1.00 | 198.00 | BF |
| 33 | 1 | 4.00 | 1548.04 | РУБ |
більше того, колонка c.briefly теж робить свій внесок у неявну освіту груп.
Яким чином? По c.id=g.currency виробляється з'єднання таблиць, а угруповання по g.currency .
Те, що в результаті гри з параметром COUNT у вас виходила завжди 1 означає, що в результуючій групі був тільки один запис
Ні, група будувалася з 1йзапис. Наскільки я це зрозумів, COUNT() повертає 1 саме тому (адже стовпці, які у групі відрізняються (щоправда, крім стовпця валют), створюються аггрегатними функціями).
(Тобто групи формуються не так як вам, можливо, потрібно, можете описати вимоги докладніше?).
Групи формуються так, як треба, кожна група -це сумарна вартість товарів у кожній валюті. Однак, мені, крім того, потрібно порахувати, скількиж елементів уцією групі.
З вашого питання не ясно, що ви хотіли б дізнатися - скільки різних валют брало участь у замовленні або скільки замовлень було в цій валюті?
Так, заробився небагато. Саме перше.
dmig [досьє]
Під "неявною" участю в освіті групи я маю на увазі, що якщо колонка не вказана в GROUP BY, і при цьому НЕ є аргументом групової функції, то результат селекту буде ідентичний тому, якби ця колонка БУЛА вказана в GROUP BY. Ваш селект і селект наведений нижче виведуть абсолютно однаковий результат (не звертайте уваги на join"и, я просто привів їх до єдиного формату запису):
Select i.id id, count(*) currencies, sum(ig.quantity) total, SUM(g.price * ig.quantity) price, c.briefly name FROM invoice i join invoice_goods ig on (ig.invoice_id = i. id) join good g on (g.id = ig.good_id) LEFT OUTER JOIN currency c ON (c.id = g.currency) group by i.id, c.briefly
Виходить що у кожному рядку результуючої вибірки є одна, і лише одна валюта (якби це було інакше, те й рядків було дві). Про кількість яких елементів у такому разі йдеться? Про пункти замовлення? Тоді ваш селект абсолютно правильний, просто по даній валюті, у цьому замовленні лише один пункт.
Давайте розглянемо схему даних:
- В одному замовленні безліч пунктів (рядків), так?
- Кожен пункт це товар у довіднику goods, так?
- Кожен товар має певну (і лише одну) валюту, це випливає із c.id = g.currency, так?
Скільки валют у замовленні? Стільки скільки в ньому пунктів із РІЗНИМИ валютами.
Складати g.price *ig.quantity має сенс тільки для пунктів в одній валюті;) (хоча кілометри з годинником, теж складати можна:) Так що ж вас не влаштовує!? Ви стверджуєте, що вам потрібно скільки різних валют брало участь у замовленні
і в такому випадку зробити це в рамках цього ж селекту без усіляких хитрощів (які швидше за все не потягне MySQL) не вийде;
Я на жаль не знавець MySQL. В oracle зробити це одним селектом можна, але чи допоможе вам така порада? Навряд чи;)
# В одному замовленні безліч пунктів (рядків), так?
# Кожен пункт це товар у довіднику goods, правда?
# Кожен товар має певну (і лише одну) валюту, це випливає із c.id = g.currency, так?
Так.
Одне замовлення: один запис у таблиці invoice, їй відповідають n(>0) записів в invoice_goods, кожній з яких відповідає 1 запис у таблиці goods, запис "валюта" у кожній з яких, у свою чергу, відповідає 1й запису в таблиці currency ( LEFT JOIN – на випадок редагування довідника валют кривими руками – таблиці типу MyISAM не підтримують зовнішніх ключів).
Скільки валют у замовленні? Стільки скільки в ньому пунктів із РІЗНИМИ валютами.
Так, саме так.
Складати g.price * ig.quantity має сенс тільки для пунктів в одній валюті;) (хоча кілометри з годинником, теж складати можна:)
Саме тому робиться угруповання з id валюти (g.currency).
В oracle зробити це одним селектом можна, але чи допоможе вам така порада?
М.Б.
Я трохи спілкувався з Oracle, з pl/sql знаком.
Варіант №1.
Виберіть a.*, count(*) over (partition by a.id) ціни від (select i.id id, sum(ig.quantity) total, SUM(g.price * ig.quantity) price, c.briefly cname FROM invoice i join invoice_goods ig on (ig.invoice_id = i.id) join good g on (g.id = ig.good_id) LEFT OUTER JOIN currency c ON (c.id = g.currency) group by i.id, c.briefly) a
Це використовує т.зв. analytic function. З ймовірністю 99% НЕ працює у MySQL.
Варіант №2.
Створюється функція, countCurrencies наприклад, яка за id замовлення повертає кількість валют яке в ньому брало участь і тоді:
Select i.id id, countCurrencies(i.id) currencies, sum(ig.quantity) total, SUM(g.price * ig.quantity) price, c.briefly name FROM invoice i join invoice_goods ig on (ig.invoice_id = i.id) join good g on (g.id = ig.good_id) LEFT OUTER JOIN currency c ON (c.id = g.currency) group by i.id, c.briefly, countCurrencies(i.id)
Може прокатати... але викликатиметься для кожної валюти кожного замовлення. Не знаю чи дає MySQL робити GROUP BY за функцією...
Варіант №3
Select i.id id, agr.cnt currencies, sum(ig.quantity) total, SUM(g.price * ig.quantity) price, c.briefly name FROM invoice i join invoice_goods ig on (ig.invoice_id = i.id ) join good g on (g.id = ig.good_id) LEFT OUTER JOIN currency c ON (c.id = g.currency) праворуч з join (select ii.id, count(distinct gg.currency) cnt from invoice ii, invoce_goods iig, добре gg, де ii.id = iig.invoice_id і gg.id = iig.good_id group by ii.id) agr on (i.id = agr.id) group by i.id, c.briefly, agr. cnt
Напевно найправильніший... і цілком можливо найробітніший варіант із усіх.
Найшвидший це варіант №1. №2 найнеефективніший, т.к. що більше валют у замовленні, то частіше вони вважаються.
№3 теж у принципі не найкращий за швидкістю, але принаймні можна покластися на кешування всередині СУБД.
результатом всіх трьох селектів буде наступне:
| id | currencies | total | price | cname | ||||
|---|---|---|---|---|---|---|---|---|
| 33 | 2 | 1.00 | 198.00 | BF | ||||
| 33 | 2 | 4.00 | 1548.04 | РУБ | ||||
для одного і того ж id цифра в колонці currencies буде завжди однакова, це те, що вам треба?
Як дізнатися кількість моделей ПК, що випускаються тим чи іншим постачальником? Як визначити середнє значення ціни комп'ютери, мають однакові технічні характеристики? На ці та інші питання, пов'язані з деякою статистичною інформацією, можна отримати відповіді за допомогою підсумкових (агрегатних) функцій. Стандартом передбачені такі агрегатні функції:
Усі ці функції повертають єдине значення. При цьому функції COUNT, MINі MAXзастосовні до будь-яких типів даних, у той час як SUMі AVGвикористовуються лише для числових полів. Різниця між функцією COUNT(*)і COUNT(<имя поля>) полягає в тому, що друга за підрахунком не враховує NULL-значення.
приклад. Знайти мінімальну та максимальну ціну на персональні комп'ютери:
приклад. Знайти наявну кількість комп'ютерів, випущених виробником А:
приклад. Якщо ж нас цікавить кількість різних моделей, що випускаються виробником А, запит можна сформулювати наступним чином (користуючись тим фактом, що в таблиці Product кожна модель записується один раз):
приклад. Знайти кількість наявних різних моделей, що випускаються виробником А. Запит схожий на попередній, в якому потрібно визначити загальну кількість моделей, що випускаються виробником А. Тут же потрібно знайти число різних моделей в таблиці PC (тобто наявних у продажу).
Для того, щоб при отриманні статистичних показників використовувалися тільки унікальні значення, аргументі агрегатних функційможна використовувати параметр DISTINCT. Інший параметр ALLвикористовується за умовчанням і передбачає підрахунок всіх значень, що повертаються в стовпці. Оператор,
Якщо нам потрібно отримати кількість моделей ПК, вироблених кожнимвиробником, то потрібно використовувати пропозиція GROUP BY, синтаксично наступного після пропозиції WHERE.
Пропозиція GROUP BY
Пропозиція GROUP BYвикористовується визначення груп вихідних рядків, яких можуть застосовуватися агрегатні функції (COUNT, MIN, MAX, AVG та SUM). Якщо ця пропозиція відсутня, і використовуються агрегатні функції, то всі стовпці з іменами, згаданими в SELECT, повинні бути включені до агрегатні функції, і ці функції будуть застосовуватися до всього набору рядків, які відповідають предикату запиту. В іншому випадку всі стовпці списку SELECT, не ввійшлив агрегатні функції повинні бути вказані у пропозиції GROUP BY. У результаті всі вихідні рядки запиту розбиваються на групи, що характеризуються однаковими комбінаціями значень цих стовпцях. Після цього до кожної групи буде застосовано агрегатні функції. Слід пам'ятати, що з GROUP BY всі значення NULL трактуються як рівні, тобто. при групуванні поля, що містить NULL-значення, всі такі рядки потраплять в одну групу.Якщо за наявності пропозиції GROUP BY, у пропозиції SELECT відсутні агрегатні функції, то запит просто поверне по одному рядку з кожної групи. Цю можливість, поряд із ключовим словом DISTINCT, можна використовувати для виключення дублікатів рядків у результуючому наборі.
Розглянемо простий приклад:
| SELECT model, COUNT(model) AS Qty_model, AVG(price) AS Avg_price FROM PC GROUP BY model; |
У цьому запиті кожної моделі ПК визначається їх кількість і середня вартість. Усі рядки з однаковими значеннями model (номер моделі) утворюють групу, і на виході SELECT обчислюються кількість значень та середні значення ціни кожної групи. Результатом виконання запиту буде наступна таблиця:
| model | Qty_model | Avg_price |
| 1121 | 3 | 850.0 |
| 1232 | 4 | 425.0 |
| 1233 | 3 | 843.33333333333337 |
| 1260 | 1 | 350.0 |
Якби в SELECT був присутній стовпець з датою, можна було б обчислювати ці показники кожної конкретної дати. Для цього потрібно додати дату як групуючий стовпчик, і тоді агрегатні функції обчислювалися б для кожної комбінації значень (модель-дата).
Існує кілька певних правил виконання агрегатних функцій:
- Якщо в результаті виконання запиту не отримано жодного рядка(або одного рядка для цієї групи), то вихідні дані для обчислення будь-якої з агрегатних функцій відсутні. У цьому випадку результат виконання функцій COUNT буде нуль, а результатом всіх інших функцій - NULL.
- Аргументагрегатної функції не може сам містити агрегатні функції(функція від функції). Тобто. в одному запиті не можна, скажімо, одержати максимум середніх значень.
- Результат виконання функції COUNT є ціле число(INTEGER). Інші агрегатні функції успадковують типи даних значень, що обробляються.
- Якщо при виконанні функції SUM був отриманий результат, що перевищує максимальне значення типу даних, що використовується, виникає помилка.
Отже, якщо запит не містить пропозиції GROUP BY, то агрегатні функції, включені в пропозиція SELECT, виконуються над усіма результуючими рядками запиту. Якщо запит містить пропозиція GROUP BY, кожен набір рядків, який має однакові значення стовпця або групи стовпців, заданих у пропозиції GROUP BY, становить групу, та агрегатні функціївиконуються кожної групи окремо.
Пропозиція HAVING
Якщо пропозиція WHEREвизначає предикат для фільтрації рядків, то пропозиція HAVINGзастосовується після угрупованнядля визначення аналогічного предикату, що фільтрує групи за значеннями агрегатних функцій. Ця пропозиція потрібна для перевірки значень, які отримані за допомогою агрегатної функціїне з окремих рядків джерела записів, визначеного в пропозиції FROM, а з груп таких рядків. Тому така перевірка не може утримуватись у пропозиції WHERE.
